
Cómo diseñar el modelo de datos a partir del diseño de un dashboard
¿Alguna vez te han enviado el diseño de un dashboard que tienes que construir en Power BI y no sabías por dónde empezar con el modelo de datos?
En este artículo te comparto un método de trabajo que uso a menudo para conseguir que el modelo de datos esté alineado con la parte visual. La idea es partir del prototipo de UX (la maqueta del informe) y, a partir de ahí, deducir qué tablas, relaciones y medidas necesitamos.
Pasos del proceso
Vamos a seguir esta secuencia:
- Analizar el dashboard.
- Hacer un borrador de dimensiones (atributos).
- Hacer un borrador de métricas (medidas).
- Agrupar las dimensiones por entidades de negocio.
- Agrupar las métricas por métricas base.
- Crear una matriz métrica vs dimensión.
- Borrador del modelo
- Ajustes del modelo para hacerlo escalable
- Validación con los datos origen
Este flujo funciona muy bien cuando el punto de partida es un diseño de UX, pero no tenemos todavía claro cómo aterrizarlo en el modelo de datos de Power BI.
1. Analizar el dashboard
Antes de tocar Power BI, conviene entender qué nos está pidiendo el dashboard:
- ¿Qué preguntas de negocio responde?
- ¿Qué tipo de análisis permite (comparar periodos, analizar por producto, por región…)?
- ¿Qué nivel de detalle se ve (por día, por mes, por cliente, por producto…)?
En esta fase revisamos:
- todos los objetos visuales (tarjetas, gráficos, tablas),
- todos los filtros (segmentadores, filtros de página, filtros de informe),
- y muy importante: todos los tooltips, porque a veces esconden métricas o atributos adicionales que no están visibles a primera vista.
Para entender mejor el proceso, vamos a analizar este ejemplo sencillo que he creado
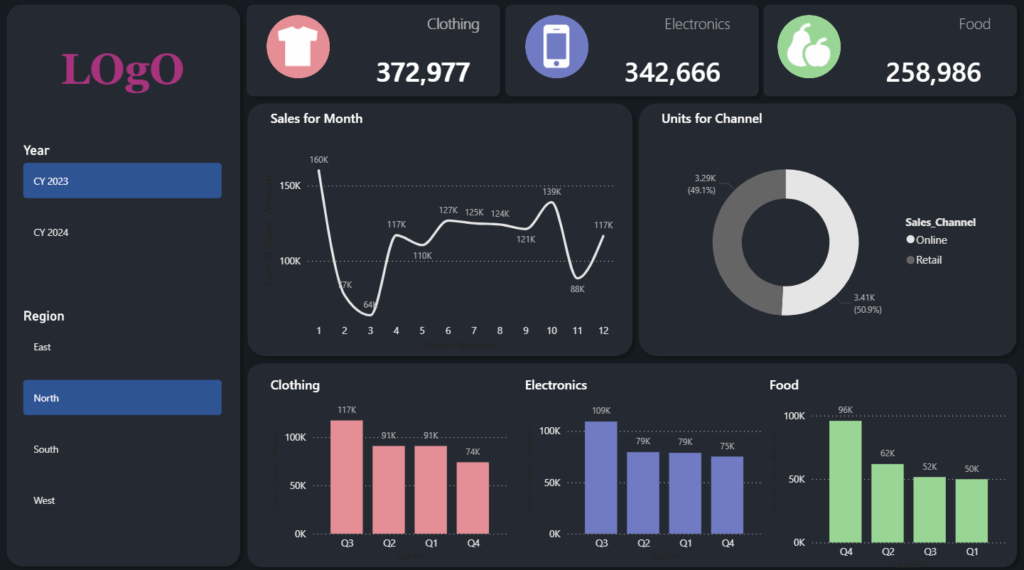
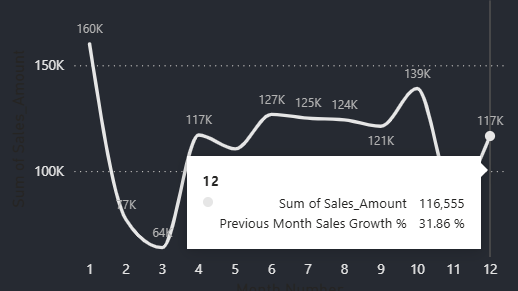
Debemos revisar también los tooltips que pueda haber en las diferentes visualizaciones como en el siguiente caso
2. Borrador de dimensiones: inventario de atributos
Primer bloque: recoger todos los atributos que aparecen en el dashboard. Son los campos por los que segmentamos, filtramos o desglosamos la información:
- Lo que aparece en filtros / slicers.
- Lo que está en ejes, leyendas, filas/columnas de gráficos y tablas.
- Lo que aparece en tooltips como contexto (categoría, canal, región…).
En el ejemplo, identificamos:
- Año
- Trimestre
- Mes
- Región
- Categoría
- Canal
Todo esto serán candidatos a columnas de dimensión.
3. Borrador de métricas: inventario de indicadores
Segundo bloque: recoger todas las métricas que se muestran:
- valores de tarjetas,
- valores numéricos en gráficos y tablas,
- KPIs con colores o iconos,
- métricas de tooltips.
En el ejemplo:
- Importe de ventas
- % crecimiento de las ventas respecto al mes anterior
- Unidades vendidas
Aquí es útil anotar si alguna métrica parece derivada de otra (por ejemplo, porcentajes de crecimiento, ratios, etc.).
4. Agrupar dimensiones por entidades de negocio
Ahora clasificamos los atributos anteriores en entidades de negocio. Nos ayuda a ver qué dimensiones podrían convertirse en tablas independientes.
Por ejemplo:
- Tiempo: Año, Trimestre, Mes
- Producto: Categoría
- Venta / Canal de venta: Región, Canal
A partir de aquí, ya se intuye un modelo tipo estrella con:
DimDate(tabla de fechas)DimProductDimSalesChannel/DimRegion(o una sola dimensión de “área de venta” si tiene sentido combinarlas)
5. Agrupar métricas por métrica base
Muchas métricas que vemos en un dashboard son derivadas de una métrica base:
| Métrica visible | Métrica base |
|---|---|
| Sales amount (importe de ventas) | Sales amount |
| % growth vs previous month (crecimiento %) | Sales amount |
| Units sold (unidades vendidas) | Units sold |
Esto es útil porque en el modelo de Power BI normalmente tendremos:
- una medida base, por ejemplo
[Sales Amount], - y sobre ella construiremos medidas derivadas:
[Sales Amount Previous Month][Sales Amount Growth %]- etc.
En el modelo de datos, estas métricas se materializan como medidas DAX, no como columnas, pero nos interesa saber qué campo numérico de la tabla de hechos las alimenta (fact table).
En este caso, podemos hablar de una tabla de hechos FactSales con, al menos:
- columna
Sales_Amount - columna
Units_Sold
6. Matriz métrica vs dimensiones
Este es un punto clave: ver con qué dimensiones se cruza cada métrica. Es lo que nos ayuda a decidir el grano de la tabla de hechos (nivel de detalle).
Si todas las métricas del ejemplo se pueden analizar por:
- Tiempo (Año, Trimestre, Mes),
- Región,
- Canal,
- Categoría,
entonces el grano natural de FactSales podría ser:
1 fila por combinación de
Date–Region–Channel–Product(o Categoría si no trabajamos a nivel de producto).
Ejemplo de matriz muy simplificada:
| Métrica | Time | Region | Channel | Category |
|---|---|---|---|---|
| Sales amount | ✔️ | ✔️ | ✔️ | ✔️ |
| Sales amount growth % | ✔️ | ✔️ | ✔️ | ✔️ |
| Units sold | ✔️ | ✔️ | ✔️ | ✔️ |
Si hubiese métricas que solo existen a nivel mensual (y no diario), podríamos plantearnos un grano diferente, pero en la práctica suele ser más flexible guardar el dato a nivel de día y luego agregar.
7. Borrador del modelo: fact table + dimensiones
Con todo lo anterior, podemos proponer un primer boceto de modelo estrella:
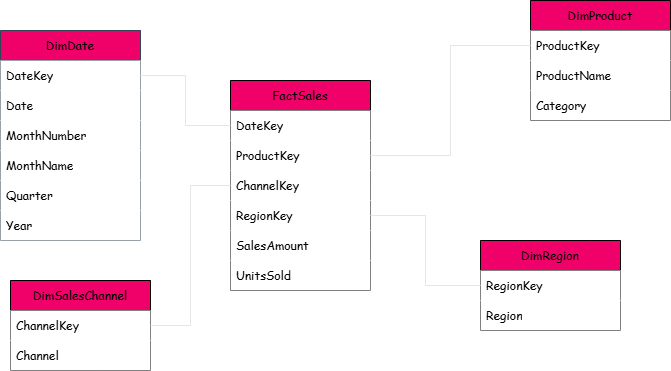
Tabla de hechos
Fact_Sales
SalesAmountUnitsSoldDateKeyProductKeyRegionKeyChannelKey
Tablas de dimensiones
DimDate
DateKey(clave — normalmente la propia fecha si usamos un date key natural)DateYearQuarterMonthNumberMonthName
DimProduct
ProductKeyProductName(si existiese)Category
DimRegion
RegionKeyRegion
DimChannel
ChannelKeyChannel
8. Ajustes del modelo para hacerlo escalable
Aquí añadimos el “toque de experiencia”: no nos quedamos solo con lo que pide el dashboard de hoy, sino que pensamos en qué puede venir mañana.
8.1. Dimensiones directamente en la fact table
Si sabemos que una dimensión no va a crecer en atributos y solo se usa para un par de campos muy simples, podríamos mantenerlos directamente en la tabla de hechos.
Por ejemplo, si Region y Channel fueran campos muy estáticos y simples, podríamos:
- dejar
RegionyChannelcomo columnas enFact_Sales, - o bien, si queremos seguir el patrón estandarizado, crear
DimRegionyDimChannelcon claves artificiales (surrogate keys).
En un entorno didáctico o pequeño, ambas opciones son aceptables; en un modelo corporativo, el patrón estrella completo suele ser preferible.
8.2. DimProduct aunque hoy solo se use Category
Aunque hoy el dashboard solo utilice Category, si en los datos origen existe el nivel de producto, puede tener sentido crear ya la DimProduct y asociar ahí la categoría:
- Hoy el dashboard solo usará
[Category]. - Mañana, si se quiere analizar por producto, el campo ya estará disponible sin rehacer el modelo.
8.3. DimDate a nivel de día
Aunque el dashboard actual solo muestre datos por mes o año, es muy recomendable que la tabla de fechas llegue a nivel de día:
- Permite usar funciones de time intelligence (YTD, MTD, comparativos con el mismo día/año anterior, etc.).
- Te da margen para futuros informes que necesiten más detalle (por ejemplo, análisis diario o por semana).
9. Validación con los datos origen
El último paso, antes de dar por cerrado el modelo, es validarlo contra las fuentes de datos:
- Comprobar que el grano de la fact table coincide con el grano real de los datos (por ejemplo, facturas, líneas de pedido, transacciones…).
- Verificar que podemos obtener todas las dimensiones planteadas (Región, Canal, Producto, Categoría, fechas…).
- Hacer una prueba rápida de medidas base:
- ¿Las ventas totales cuadran con el sistema origen?
- ¿Al segmentar por Región/Canal/Categoría las cifras tienen sentido?
Si algo no encaja, volvemos al esquema y ajustamos:
- añadiendo columnas clave que falten,
- corrigiendo relaciones,
- o redefiniendo el grano de la fact table.
Conclusión
Cuando partimos de un diseño de dashboard, el objetivo no es “adivinar” el modelo perfecto a la primera, sino usar el diseño como guía para:
- Identificar dimensiones y métricas.
- Deducir el grano de la tabla de hechos.
- Proponer un modelo estrella simple, coherente con las preguntas de negocio.
- Ajustarlo con el conocimiento que tenemos de los datos y del futuro del proyecto.
Este enfoque te permite ir de la UX al modelo de datos de forma estructurada, y facilita que el informe de Power BI sea:
- fácil de mantener,
- fácil de ampliar,
- y robusto cuando lleguen nuevas necesidades (nuevas métricas, nuevos ejes de análisis, nuevos dashboards sobre el mismo modelo).